Externaliser les contextes de vos projets Talend Open Studio for Data Integration
28 août 2012
Il y a quelques semaines, j’ai écrit dans un article, une petite introduction à la reprise de données grâce au formidable outil qu’est Talend Open Studio for Data Integration.
Dans ce nouvel article, je vous propose de voir comment externaliser les contextes.
Pourquoi utiliser des contextes ?
Lorsque vous développez un projet, vous avez généralement plusieurs environnements :
- l’environnement de développement ;
- l’environnement de recette ;
- l’environnement de production.
En toute logique, chaque environnement possède sa base de données. On a donc généralement trois bases de données avec le même schéma.
Puisque nos bases de données sont identiques, il serait dommage de créer trois projets sous Talend ayant exactement les mêmes jobs, uniquement pour avoir des connexions aux bases de données différentes.
L’idéal serait de pouvoir choisir l’environnement dans lequel on souhaite jouer le scénario de reprise de données en quelques clics. C’est ce que nous allons voir dans ce tutoriel.
Objectif de ce tutoriel
Dans ce tutoriel, nous allons créer ensemble un projet avec deux contextes : celui de développement afin que nous puissions tester notre reprise de données et celui de production.
Le projet avec le contexte de production sera livré celui livré à notre client virtuel afin qu’il puisse exécuter le projet chez lui.
Puisque notre client ne connaît pas Talend Open Studio for Data Integration et qu’il est impensable de lui faire installer, nous allons lui livrer un script autonome dans lequel il devra se contenter de renseigner les informations de connexion aux bases de données.
Les bases de données
Je vous propose de repartir du même exemple que mon précédent tutoriel.
La source
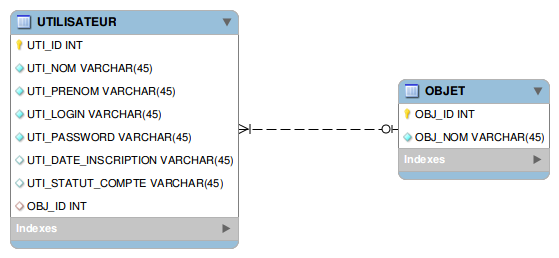
Dans notre application imaginaire, nous avons donc une première table représentant un utilisateur. Un utilisateur possède un nom, un prénom, un login et un mot de passe. Il peut également posséder une date d’inscription et un statut (ces deux derniers paramètres sont facultatifs). Toutes ces données sont des chaînes de caractères.
Un utilisateur peut également posséder un objet, mais ce n’est pas obligatoire. On part ici du principe que le texte contenu dans le statut est formaté toujours de la même manière puisqu’il est issu d’une liste statique alimentée en dur dans l’application.
Voici le script de création de la base avec quelques données.
-- phpMyAdmin SQL Dump
-- version 3.4.5
-- http://www.phpmyadmin.net
--
-- Client: localhost
-- Généré le : Dim 10 Juin 2012 à 17:57
-- Version du serveur: 5.5.16
-- Version de PHP: 5.3.8
SET SQL_MODE="NO_AUTO_VALUE_ON_ZERO";
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
--
-- Base de données: `DEMONSTRATION_SOURCE`
--
CREATE DATABASE `DEMONSTRATION_SOURCE` DEFAULT CHARACTER SET latin1 COLLATE latin1_swedish_ci;
USE `DEMONSTRATION_SOURCE`;
-- --------------------------------------------------------
--
-- Structure de la table `OBJET`
--
CREATE TABLE IF NOT EXISTS `OBJET` (
`OBJ_ID` int(11) NOT NULL AUTO_INCREMENT,
`OBJ_NOM` varchar(45) NOT NULL,
PRIMARY KEY (`OBJ_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=4 ;
--
-- Contenu de la table `OBJET`
--
INSERT INTO `OBJET` (`OBJ_ID`, `OBJ_NOM`) VALUES
(1, 'Voiture'),
(2, 'Télévision'),
(3, 'Téléphone');
-- --------------------------------------------------------
--
-- Structure de la table `UTILISATEUR`
--
CREATE TABLE IF NOT EXISTS `UTILISATEUR` (
`UTI_ID` int(11) NOT NULL AUTO_INCREMENT,
`UTI_NOM` varchar(45) NOT NULL,
`UTI_PRENOM` varchar(45) NOT NULL,
`UTI_LOGIN` varchar(45) NOT NULL,
`UTI_PASSWORD` varchar(45) NOT NULL,
`UTI_DATE_INSCRIPTION` varchar(45) DEFAULT NULL,
`UTI_STATUT_COMPTE` varchar(45) DEFAULT NULL,
`OBJ_ID` int(11) DEFAULT NULL,
PRIMARY KEY (`UTI_ID`),
KEY `fk_UTILISATEUR_OBJET` (`OBJ_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=6 ;
--
-- Contenu de la table `UTILISATEUR`
--
INSERT INTO `UTILISATEUR` (`UTI_ID`, `UTI_NOM`, `UTI_PRENOM`, `UTI_LOGIN`, `UTI_PASSWORD`, `UTI_DATE_INSCRIPTION`, `UTI_STATUT_COMPTE`, `OBJ_ID`) VALUES
(1, 'DOE', 'John', 'jdoe', 'mdp_jdoe', '12/12/2012', 'Ancien', 1),
(2, 'POPPINS', 'Marie', 'mpoppins', 'mdp_mpoppins', NULL, NULL, 2),
(3, 'ROLAND', 'Ludovic', 'lroland', 'mdp_lroland', '14/04/2007', NULL, 3),
(4, 'SUNG', 'Sam', 'ssung', 'mdpssung', NULL, 'Débutant', NULL),
(5, 'MAN', 'Batte', 'bman', 'mdp_bman', '05/06/2009', 'Débutant', NULL);
--
-- Contraintes pour les tables exportées
--
--
-- Contraintes pour la table `UTILISATEUR`
--
ALTER TABLE `UTILISATEUR`
ADD CONSTRAINT `fk_UTILISATEUR_OBJET` FOREIGN KEY (`OBJ_ID`) REFERENCES `OBJET` (`OBJ_ID`) ON DELETE NO ACTION ON UPDATE NO ACTION;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
La destination
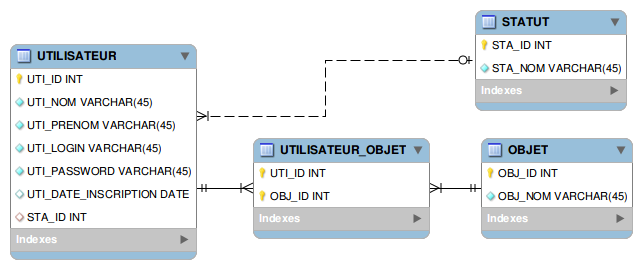
Qu’est-ce qui change par rapport à la base de données source ?
Tout d’abord, au niveau de l’utilisateur, la date d’inscription n’est plus une chaîne de caractère mais une date. On a également décidé de sortir le statut pour rendre nos éléments les plus atomiques possibles. Finalement, un utilisateur peut désormais posséder plusieurs objets. On remarque donc l’apparition d’une table intermédiaire entre les tables objet et utilisateur.
Voici le code de création de cette nouvelle base de données.
-- phpMyAdmin SQL Dump
-- version 3.4.5
-- http://www.phpmyadmin.net
--
-- Client: localhost
-- Généré le : Dim 10 Juin 2012 à 17:59
-- Version du serveur: 5.5.16
-- Version de PHP: 5.3.8
SET SQL_MODE="NO_AUTO_VALUE_ON_ZERO";
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
--
-- Base de données: `DEMONSTRATION_DESTINATION`
--
CREATE DATABASE `DEMONSTRATION_DESTINATION` DEFAULT CHARACTER SET latin1 COLLATE latin1_swedish_ci;
USE `DEMONSTRATION_DESTINATION`;
-- --------------------------------------------------------
--
-- Structure de la table `OBJET`
--
CREATE TABLE IF NOT EXISTS `OBJET` (
`OBJ_ID` int(11) NOT NULL AUTO_INCREMENT,
`OBJ_NOM` varchar(45) NOT NULL,
PRIMARY KEY (`OBJ_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Structure de la table `STATUT`
--
CREATE TABLE IF NOT EXISTS `STATUT` (
`STA_ID` int(11) NOT NULL AUTO_INCREMENT,
`STA_NOM` varchar(45) NOT NULL,
PRIMARY KEY (`STA_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Structure de la table `UTILISATEUR`
--
CREATE TABLE IF NOT EXISTS `UTILISATEUR` (
`UTI_ID` int(11) NOT NULL AUTO_INCREMENT,
`UTI_NOM` varchar(45) NOT NULL,
`UTI_PRENOM` varchar(45) NOT NULL,
`UTI_LOGIN` varchar(45) NOT NULL,
`UTI_PASSWORD` varchar(45) NOT NULL,
`UTI_DATE_INSCRIPTION` date DEFAULT NULL,
`STA_ID` int(11) DEFAULT NULL,
PRIMARY KEY (`UTI_ID`),
KEY `fk_UTILISATEUR_STATUT` (`STA_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Structure de la table `UTILISATEUR_OBJET`
--
CREATE TABLE IF NOT EXISTS `UTILISATEUR_OBJET` (
`UTI_ID` int(11) NOT NULL,
`OBJ_ID` int(11) NOT NULL,
PRIMARY KEY (`UTI_ID`,`OBJ_ID`),
KEY `fk_UTILISATEUR_has_OBJET_OBJET1` (`OBJ_ID`),
KEY `fk_UTILISATEUR_has_OBJET_UTILISATEUR1` (`UTI_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Contraintes pour les tables exportées
--
--
-- Contraintes pour la table `UTILISATEUR`
--
ALTER TABLE `UTILISATEUR`
ADD CONSTRAINT `fk_UTILISATEUR_STATUT` FOREIGN KEY (`STA_ID`) REFERENCES `STATUT` (`STA_ID`) ON DELETE NO ACTION ON UPDATE NO ACTION;
--
-- Contraintes pour la table `UTILISATEUR_OBJET`
--
ALTER TABLE `UTILISATEUR_OBJET`
ADD CONSTRAINT `fk_UTILISATEUR_has_OBJET_UTILISATEUR1` FOREIGN KEY (`UTI_ID`) REFERENCES `UTILISATEUR` (`UTI_ID`) ON DELETE NO ACTION ON UPDATE NO ACTION,
ADD CONSTRAINT `fk_UTILISATEUR_has_OBJET_OBJET1` FOREIGN KEY (`OBJ_ID`) REFERENCES `OBJET` (`OBJ_ID`) ON DELETE NO ACTION ON UPDATE NO ACTION;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
Configuration des connexions aux bases de données
Après la création du projet dans Talend Open Studio for Data Integration, il est temps de passer à la configuration des connexions aux bases de données.
Connexion à la source
De manière classique, rendez-vous dans l’onglet de gauche et plus précisément dans la catégorie Métadonnées. Faites un clic droit sur Bases de données puis cliquez sur créer une connexion.
Dans la fenêtre qui apparaît, remplissez les informations demandées (notamment le Nom) puis cliquez sur le bouton Suivant. Remplissez alors les informations de connexion.
Voici par exemple ce que ça donne pour la base de données source.
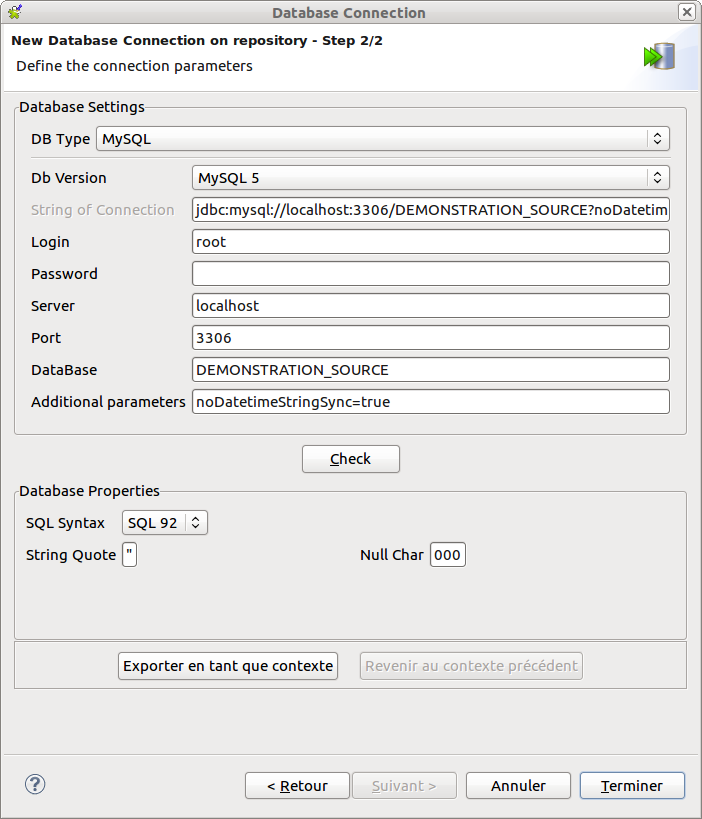
Vous pouvez vérifier la bonne connexion via le bouton Check.
Dans le bas de la page, vous pouvez apercevoir le bouton Exporter en tant que contexte. Cliquez dessus !
Dans la fenêtre qui apparaît, remplissez les informations demandées (notamment le Nom) puis cliquez sur le bouton Suivant.
Dans cette nouvelle fenêtre, vous pouvez notamment voir un onglet Table des valeurs. Cette onglet vous permet de visualiser les paramètres de connexion à la base de données suivant le contexte utilisé. Pour le moment, nous n’en avons qu’un, il s’agit du contexte par défaut.
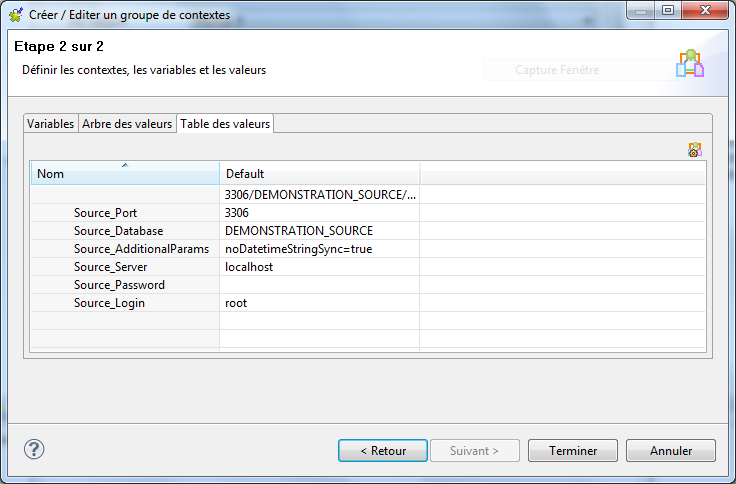
Cliquez sur  pour faire apparaître une nouvelle fenêtre. C’est dans celle-ci que nous allons paramétrer de nouveaux contextes.
pour faire apparaître une nouvelle fenêtre. C’est dans celle-ci que nous allons paramétrer de nouveaux contextes.
Je vous propose ici de créer un nouveau contexte que l’on va appeler PRODUCTION. Rien de bien compliqué, cliquez sur Nouveau puis saisissez le nom du contexte.
Voici ce que vous devriez avoir après sa saisie :
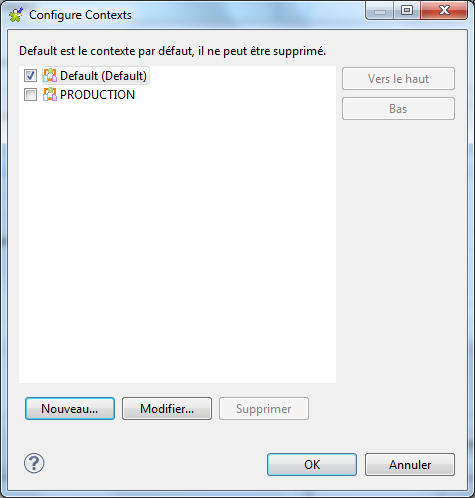
Cliquez sur OK. Vous pouvez maintenant voir que dans l’onglet Table des valeurs. Le contexte PRODUCTION apparaît bien avec une copie des valeurs du contexte par défaut.
Puisque nous ignorons les informations de connexion aux bases de production, nous allons supprimer ces valeurs.
Pour ce faire, c’est assez simple, allez dans l’onglet Arbre des valeurs et supprimez les valeurs correspondant au contexte PRODUCTION.
De retour, dans l’onglet Table des valeurs, vous devriez avoir quelque chose comme ça :
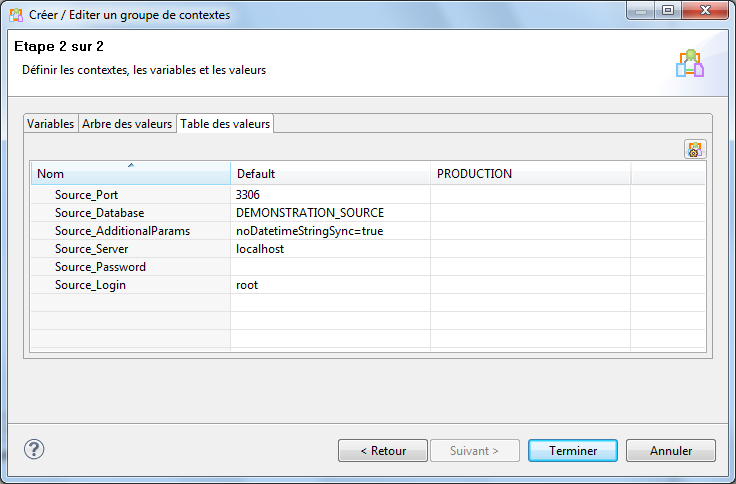
Cliquez ensuite sur Terminer. Faites de même sur la fenêtre de configuration de connexion à la base de données et choisissez de travailler avec le contexte Default si on vous le demande.
Connexion à la destination
Faites exactement la même chose avec la base de données DEMONSTRATION_DESTINATION.
Si vous faites un tour dans l’onglet de gauche et que vous déroulez la catégorie Contextes, vous devriez y voir les contextes correspondant à nos bases de données source et destination.
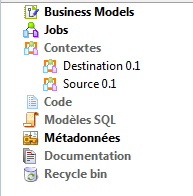
La suite
Pour la suite, je vais vous demander de vous référer à mon précédent tutoriel. Voici ce que vous devez faire :
- rapatrier les schémas ;
- créer le job Statut ;
- créer le job Objet ;
- créer le job Utilisateur ;
- créer le job UtilisateurObjet ;
A noter que chaque fois que l’on vous demande si l’on doit ajouter le contexte, dites Oui !
Pour créer ces jobs, vous pouvez vous référer à mon autre tutoriel.
Un job de jobs
Nous allons maintenant créer un job contenant tous les autres jobs. L’objectif est ici de n’avoir à exécuter qu’un seul job pour réaliser notre reprise de données. Ce job va faire appel aux autres, dans l’ordre que nous aurons choisis. Cela permet notamment de s’assurer qu’on ne viole pas des contraintes en exécutant les jobs dans un ordre aléatoire.
Appelons par exemple ce nouveau job execute. Sur l’espace de travail de ce nouveau job, faites glisser les autres jobs. Des tRunJob sont alors créés.
Reliez les ensuite comme dans la capture d’écran suivante :

Quand nous allons exécuter notre job execute, ce dernier va lancer l’exécution du job Statut, puis l’exécution du job Objet, puis l’exécution du job Utilisateur et finalement l’exécution du job UtilisateurObjet dans cet ordre.
Sélectionné ensuite chacun de ces composants tRunJob et cochez la case Transmettre tout le contexte. C’est cette option qui va permettre plus tard de configurer uniquement le contexte du job père afin qu’il le transmette automatiquement aux jobs fils sans configurer chacun d’entre eux.
Toujours dans le job execute, rendez-vous maintenant dans l’onglet contexte. Normalement, son contenu est vide, c’est pourquoi nous allons le remplir !
Dans le sous onglet Variables, en bas du tableau, cliquez sur . Dans la nouvelle fenêtre qui s’affiche, cliquez sur Sélectionner Tout puis sur OK.
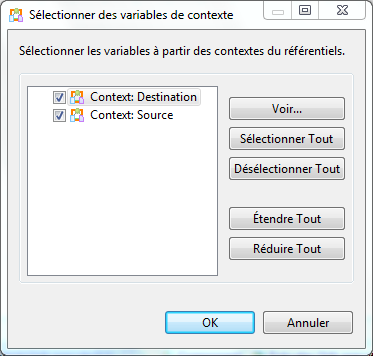
Une nouvelle fenêtre devrait s’afficher. Encore une fois, cliquez sur Sélectionner Tout puis sur OK.
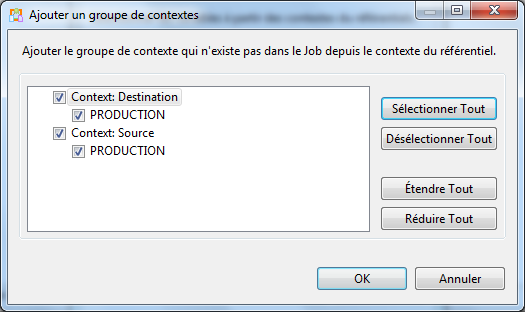
Exporter le job
Nous allons maintenant exporter le job execute en tant que job indépendant afin de livrer le script à notre client virtuel.
Pour ce faire, dans l’onglet de gauche, faîtes un clic droit sur le job execute puis sélectionnez Exporter le job.
La fenêtre suivante doit apparaître :
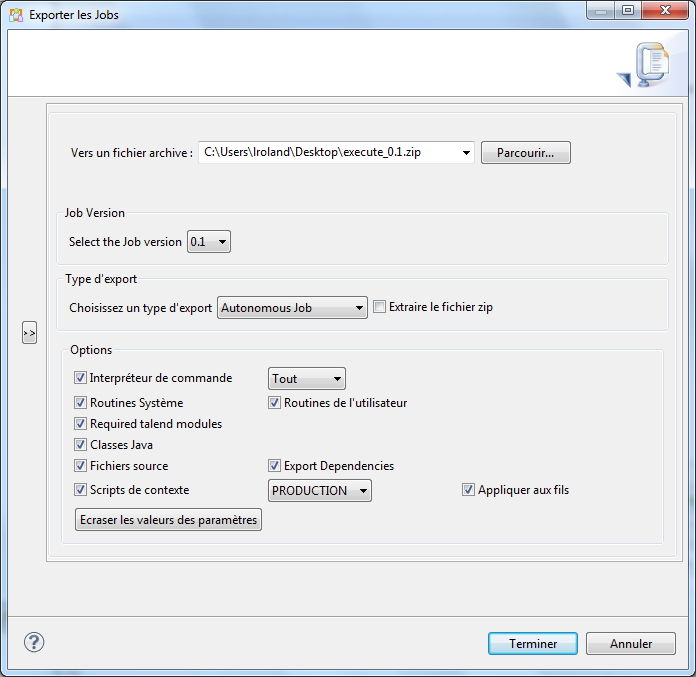
Plusieurs choses sont ici importantes. Tout d’abord, le job doit impérativement être exporté en Autonomous Job. Il est également très important que le contexte soit le contexte de PRODUCTION **et qu’il soit **appliqué aux fils.
Exécuter le script
Maintenant que notre job est exporté sous la forme d’un script, voyons comment notre client virtuel doit configurer le script puis l’exécuter.
La configuration
Rendez-vous dans le dossier “execute_0.1\execute\tuto\execute_0_1\contexts” (tuto étant le nom de mon projet Talend) et ouvrez le fichier PRODUCTION.properties.
Il doit normalement ressembler à ça :
Source_Server=
Source_AdditionalParams=
Destination_Database=
Destination_Password=
Source_Login=
Destination_AdditionalParams=
Destination_Server=
Source_Password=
Source_Database=
Destination_Port=
Destination_Login=
Source_Port=
Complétez le avec les informations des bases de données. Par exemple :
Source_Server=localhost
Source_AdditionalParams=
Destination_Database=DEMONSTRATION_DESTINATION
Destination_Password=
Source_Login=root
Destination_AdditionalParams=
Destination_Server=localhost
Source_Password=
Source_Database=DEMONSTRATION_SOURCE
Destination_Port=3306
Destination_Login=root
Source_Port=3306
L’exécution
Il ne vous reste plus qu’à jouer le scénario de reprise en exécutant le script execute_run.bat **ou **execute_run.sh suivant votre système d’exploitation qui se trouve dans le répertoire “execute_0.1\execute”.