La reprise de données avec Talend Open Studio for Data Integration
9 juin 2012
Actuellement en stage, j’ai eu l’occasion de découvrir le logiciel Talend Open Studio for Data Integration afin de réaliser la reprise de données entre deux applications.
Vous l’aurez donc compris, ce billet vous propose un petit cas pratique assez simple qui a pour objectif de vous servir d’introduction à l’utilisation de ce soft gratuit et multi plate-forme.
L’énoncé
L’exercice que je vous propose consiste à réaliser une reprise de données entre deux bases de données MySQL. Libre à vous d’adapter ce tutoriel avec un web service, un fichier XML, un fichier Excel, etc.
La source
Voilà le schéma de la base de données source.
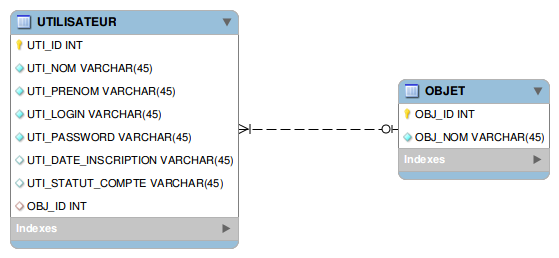
Dans notre application imaginaire, nous avons donc une première table représentant un utilisateur. Un utilisateur possède un nom, un prénom, un login et un mot de passe. Il peut également posséder une date d’inscription et un statut (ces deux derniers paramètres sont facultatifs). Toutes ces données sont des chaînes de caractères.
Un utilisateur peut également posséder un objet, mais ce n’est pas obligatoire. On part ici du principe que le texte contenu dans le statut est formaté toujours de la même manière puisqu’il est issu d’une liste statique alimentée en dur dans l’application.
Voici le script de création de la base avec quelques données.
-- phpMyAdmin SQL Dump
-- version 3.4.5
-- http://www.phpmyadmin.net
--
-- Client: localhost
-- Généré le : Dim 10 Juin 2012 à 17:57
-- Version du serveur: 5.5.16
-- Version de PHP: 5.3.8
SET SQL_MODE="NO_AUTO_VALUE_ON_ZERO";
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
--
-- Base de données: `DEMONSTRATION_SOURCE`
--
CREATE DATABASE `DEMONSTRATION_SOURCE` DEFAULT CHARACTER SET latin1 COLLATE latin1_swedish_ci;
USE `DEMONSTRATION_SOURCE`;
-- --------------------------------------------------------
--
-- Structure de la table `OBJET`
--
CREATE TABLE IF NOT EXISTS `OBJET` (
`OBJ_ID` int(11) NOT NULL AUTO_INCREMENT,
`OBJ_NOM` varchar(45) NOT NULL,
PRIMARY KEY (`OBJ_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=4 ;
--
-- Contenu de la table `OBJET`
--
INSERT INTO `OBJET` (`OBJ_ID`, `OBJ_NOM`) VALUES
(1, 'Voiture'),
(2, 'Télévision'),
(3, 'Téléphone');
-- --------------------------------------------------------
--
-- Structure de la table `UTILISATEUR`
--
CREATE TABLE IF NOT EXISTS `UTILISATEUR` (
`UTI_ID` int(11) NOT NULL AUTO_INCREMENT,
`UTI_NOM` varchar(45) NOT NULL,
`UTI_PRENOM` varchar(45) NOT NULL,
`UTI_LOGIN` varchar(45) NOT NULL,
`UTI_PASSWORD` varchar(45) NOT NULL,
`UTI_DATE_INSCRIPTION` varchar(45) DEFAULT NULL,
`UTI_STATUT_COMPTE` varchar(45) DEFAULT NULL,
`OBJ_ID` int(11) DEFAULT NULL,
PRIMARY KEY (`UTI_ID`),
KEY `fk_UTILISATEUR_OBJET` (`OBJ_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=6 ;
--
-- Contenu de la table `UTILISATEUR`
--
INSERT INTO `UTILISATEUR` (`UTI_ID`, `UTI_NOM`, `UTI_PRENOM`, `UTI_LOGIN`, `UTI_PASSWORD`, `UTI_DATE_INSCRIPTION`, `UTI_STATUT_COMPTE`, `OBJ_ID`) VALUES
(1, 'DOE', 'John', 'jdoe', 'mdp_jdoe', '12/12/2012', 'Ancien', 1),
(2, 'POPPINS', 'Marie', 'mpoppins', 'mdp_mpoppins', NULL, NULL, 2),
(3, 'ROLAND', 'Ludovic', 'lroland', 'mdp_lroland', '14/04/2007', NULL, 3),
(4, 'SUNG', 'Sam', 'ssung', 'mdpssung', NULL, 'Débutant', NULL),
(5, 'MAN', 'Batte', 'bman', 'mdp_bman', '05/06/2009', 'Débutant', NULL);
--
-- Contraintes pour les tables exportées
--
--
-- Contraintes pour la table `UTILISATEUR`
--
ALTER TABLE `UTILISATEUR`
ADD CONSTRAINT `fk_UTILISATEUR_OBJET` FOREIGN KEY (`OBJ_ID`) REFERENCES `OBJET` (`OBJ_ID`) ON DELETE NO ACTION ON UPDATE NO ACTION;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
La destination
Voici maintenant le schéma de la base de données de destination.
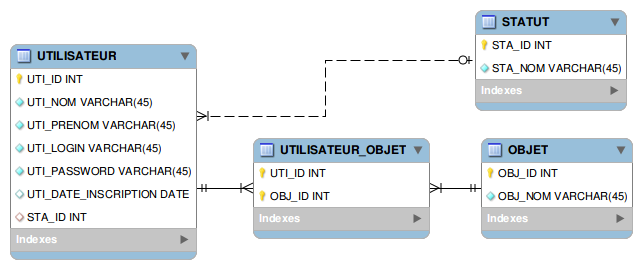
Qu’est-ce qui change par rapport à la base de données source ?
Tout d’abord, au niveau de l’utilisateur, la date d’inscription n’est plus une chaîne de caractère mais une date. On a également décidé de sortir le statut pour rendre nos éléments les plus atomiques possibles. Finalement, un utilisateur peut désormais posséder plusieurs objets. On remarque donc l’apparition d’une table intermédiaire entre les tables objet et utilisateur.
Voici le code de création de cette nouvelle base de données.
-- phpMyAdmin SQL Dump
-- version 3.4.5
-- http://www.phpmyadmin.net
--
-- Client: localhost
-- Généré le : Dim 10 Juin 2012 à 17:59
-- Version du serveur: 5.5.16
-- Version de PHP: 5.3.8
SET SQL_MODE="NO_AUTO_VALUE_ON_ZERO";
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
--
-- Base de données: `DEMONSTRATION_DESTINATION`
--
CREATE DATABASE `DEMONSTRATION_DESTINATION` DEFAULT CHARACTER SET latin1 COLLATE latin1_swedish_ci;
USE `DEMONSTRATION_DESTINATION`;
-- --------------------------------------------------------
--
-- Structure de la table `OBJET`
--
CREATE TABLE IF NOT EXISTS `OBJET` (
`OBJ_ID` int(11) NOT NULL AUTO_INCREMENT,
`OBJ_NOM` varchar(45) NOT NULL,
PRIMARY KEY (`OBJ_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Structure de la table `STATUT`
--
CREATE TABLE IF NOT EXISTS `STATUT` (
`STA_ID` int(11) NOT NULL AUTO_INCREMENT,
`STA_NOM` varchar(45) NOT NULL,
PRIMARY KEY (`STA_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Structure de la table `UTILISATEUR`
--
CREATE TABLE IF NOT EXISTS `UTILISATEUR` (
`UTI_ID` int(11) NOT NULL AUTO_INCREMENT,
`UTI_NOM` varchar(45) NOT NULL,
`UTI_PRENOM` varchar(45) NOT NULL,
`UTI_LOGIN` varchar(45) NOT NULL,
`UTI_PASSWORD` varchar(45) NOT NULL,
`UTI_DATE_INSCRIPTION` date DEFAULT NULL,
`STA_ID` int(11) DEFAULT NULL,
PRIMARY KEY (`UTI_ID`),
KEY `fk_UTILISATEUR_STATUT` (`STA_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Structure de la table `UTILISATEUR_OBJET`
--
CREATE TABLE IF NOT EXISTS `UTILISATEUR_OBJET` (
`UTI_ID` int(11) NOT NULL,
`OBJ_ID` int(11) NOT NULL,
PRIMARY KEY (`UTI_ID`,`OBJ_ID`),
KEY `fk_UTILISATEUR_has_OBJET_OBJET1` (`OBJ_ID`),
KEY `fk_UTILISATEUR_has_OBJET_UTILISATEUR1` (`UTI_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Contraintes pour les tables exportées
--
--
-- Contraintes pour la table `UTILISATEUR`
--
ALTER TABLE `UTILISATEUR`
ADD CONSTRAINT `fk_UTILISATEUR_STATUT` FOREIGN KEY (`STA_ID`) REFERENCES `STATUT` (`STA_ID`) ON DELETE NO ACTION ON UPDATE NO ACTION;
--
-- Contraintes pour la table `UTILISATEUR_OBJET`
--
ALTER TABLE `UTILISATEUR_OBJET`
ADD CONSTRAINT `fk_UTILISATEUR_has_OBJET_UTILISATEUR1` FOREIGN KEY (`UTI_ID`) REFERENCES `UTILISATEUR` (`UTI_ID`) ON DELETE NO ACTION ON UPDATE NO ACTION,
ADD CONSTRAINT `fk_UTILISATEUR_has_OBJET_OBJET1` FOREIGN KEY (`OBJ_ID`) REFERENCES `OBJET` (`OBJ_ID`) ON DELETE NO ACTION ON UPDATE NO ACTION;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
Talend Open Studio for Data Integration
Il est maintenant temps de passer à l’étape la plus amusante de ce petit tutoriel : la reprise des données.
La connexion aux bases de données
Après avoir créé un nouveau projet, la première étape consiste à créer une connexion à nos deux bases de données.
Tout se passe dans l’onglet de gauche. Rendez-vous dans la catégorie Métadonnées puis Bases de données. Un petit clic droit vous permet alors de créer une nouvelle connexion.
Dans la fenêtre qui apparaît, remplissez les informations demandées (notamment le Nom) puis cliquez sur le bouton Suivant. Remplissez alors les informations de connexion.
Voici par exemple ce que ça donne pour la base de données source.
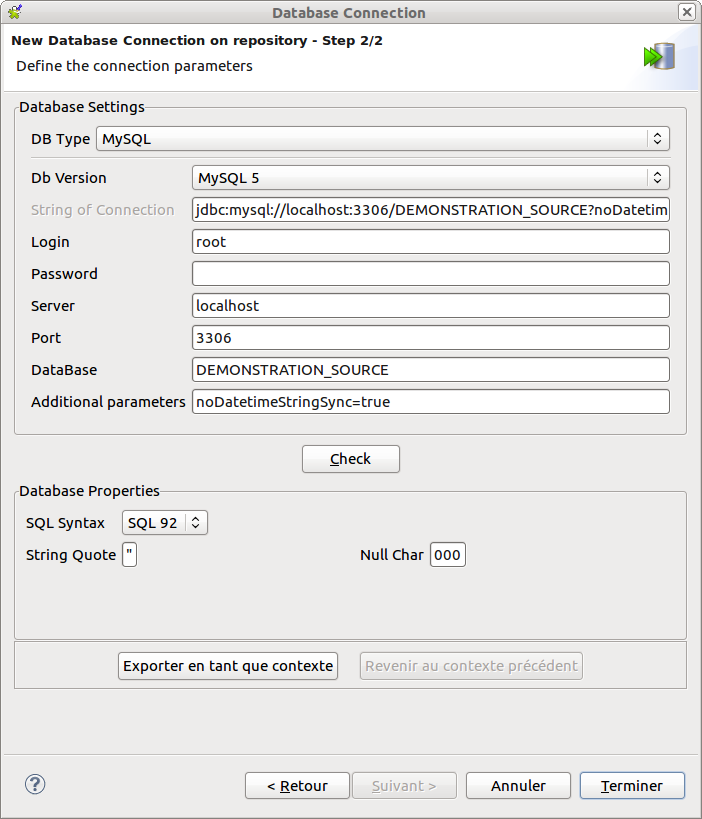
Vous pouvez vérifier la bonne connexion via le bouton Check.
Reproduisez ensuite l’opération avec la base de destination. Votre onglet gauche devrait maintenant ressembler à ça :
Rapatrier les schémas
Maintenant que les connexions à vos bases de données fonctionnent, nous allons rapatrier les schémas.
Pour ce faire, faites un clic droit sur le nom de la base de données puis cliquez sur Retrieve schema. Cliquez sur le bouton Suivant puis sélectionnez la base de données dans la liste.
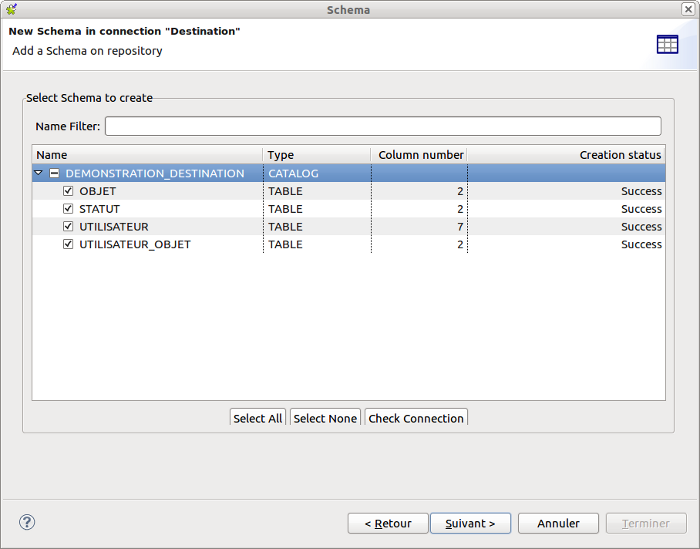
Cliquez ensuite sur Suivant puis Terminer.
Faites ensuite la même chose avec l’autre base de données. Votre onglet gauche s’est normalement encore enrichi.
Les jobs
Il est maintenant temps de passer aux choses sérieuses ! Notre base de données destination contient quatre tables, c’est pourquoi je vous propose de créer quatre jobs. Chaque job aura pour objectif d’alimenter une table.
Le statut
Nous allons commencer avec le plus simple : l’alimentation de la table statut.
Pour créer le job, rendez-vous dans l’onglet de gauche, puis sur la catégorie Jobs, faites un clic droit puis Créer un job. Saisissez les informations demandées comme le Nom puis cliquez sur Terminer. Votre espace de travail apparaît alors à l’écran.
Le but est de remplir la table STATUT de la base de données DEMONSTRATION_DESTINATION. Nous allons donc la faire glisser sur notre espace de travail depuis le dossier Tables schemas de la base de données du même nom.
La fenêtre suivante apparaît alors.
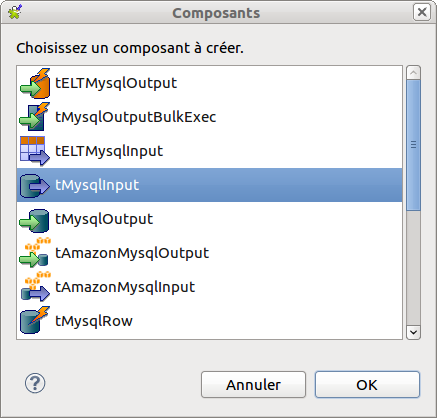
Puisqu’il s’agit de la table que l’on souhaite alimenter, nous allons indiquer qu’il s’agit d’une tMysqlOutput.
Vous vous en doutez, si nous avons une table output, nous allons également avoir besoin d’une table input ! Dans notre cas, il s’agit de la table qui contient les données, soit la table UTILISATEUR de la base de données DEMONSTRATION_SOURCE.
Vos deux tables sont donc normalement sur votre espace de travail. Il est maintenant temps de les relier !
Pour xe faire, chercher l’élément tMap dans l’onglet de droite puis faites le glisser sur votre espace de travail. Il faut maintenant relier tous ces éléments ensemble.
Faites un clic droit sur la table UTILISATEUR puis sélectionnez ligne et finalement main puis faites glisser jusqu’au tMap. la table UTILISATEUR est reliée ! Relions maintenant la table STATUT. Pour ce faire, faites un clic droit sur le tMap puis sélectionnez ligne et new output. Faites glisser jusqu’à la table STATUT. Saisissez le nom de la sortie par exemple mapStatut puis à la question «Récupérer le schéma du composant cible» répondez oui.
Voici ce que vous devriez avoir :
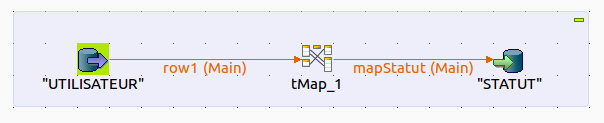
Double cliquez sur le tMap pour faire apparaître un nouvel écran. C’est dans cet écran que nous allons faire concorder les différents champs entre les deux tables.
Ce qui nous intéresse dans notre cas, c’est faire concorder le champ UTI_STATUT_COMPTE avec le champ STA_NOM. Nous allons donc faire une action de glisser/déposer du champ UTI_STATUT_COMPTE dans la colonne Expression du champ STA_NOM du mapStatut.
Vous devriez alors avoir quelque chose comme ça :
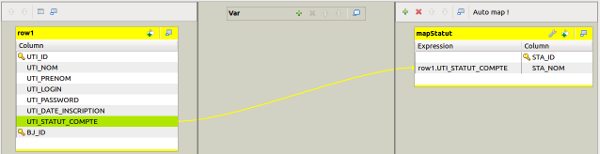
Vous pouvez maintenant cliquer sur OK pour fermer la fenêtre et revenir sur votre espace de travail.
Nous allons maintenant ajouter un tLogRow entre notre tMap et notre table STATUT. Cet élément va nous permettre de voir les lignes qui vont alimenter notre table STATUT. Pour ce faire, cherchez l’élément dans l’onglet de droite, plus faites le glisser sur la liaison que l’on a nommé mapStatut.

Nous pouvons tenter d’exécuter notre job et voir les données qui alimente notre table STATUT. Voici ce que le tLogRow devrait vous dire :
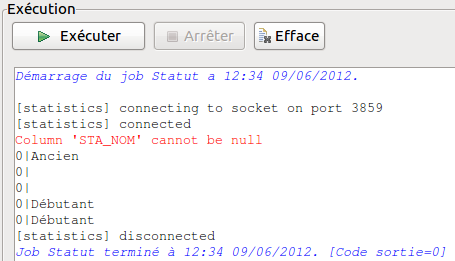
On remarque donc plusieurs problèmes :
- le doublon de la valeur «Débutant» ;
- les valeurs null ;
- la clef primaire ne semble pas s’auto-incrémenter.
Je vous propose de commencer par le problème de la clef primaire. La solution est assez simple. Il suffit de double cliquer sur le tMap. Dans l’écran qui apparaît, supprimez le champ STA_ID dans le mapStatut. C’est tout !
Continuons avec l’élimination des éventuels doublons. Nous allons utiliser l’élément qui s’appelle tUniqRow. Comme pour le tLogRow, faites glisser l’élément entre le tMap et le tLogRow :
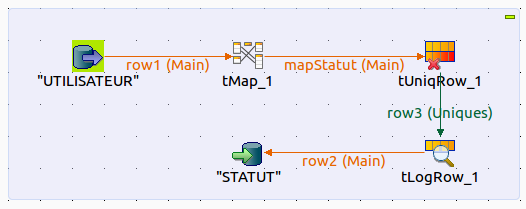
Il faut maintenant le configurer. Double cliquez sur le tUniqRow. Dans l’onglet du bas, un tableau s’affiche. Assurez-vous juste que le champ STA_NOM apparaisse bien dedans comme dans la capture d’écran ci-dessous :
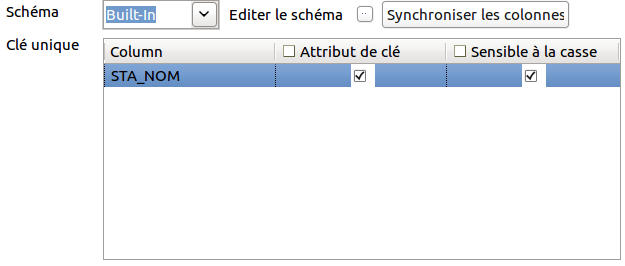
Il ne nous reste plus que le problème des valeurs null à régler. Pour le solutionner, nous allons encore utiliser un nouvel élément : le tFilterRow.
Cherchez l’élément puis faites le glisser entre le tUniqRow et le tLogRow.
Double cliquez sur l’élément tFilterRow puis dans l’onglet Paramètres simples, ajoutez la ligne suivante :
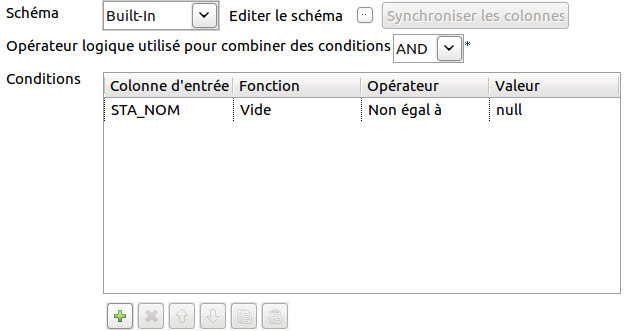
Vous pouvez maintenant lancer l’exécution du job. Le log devrait alors vous afficher quelque chose comme ça :
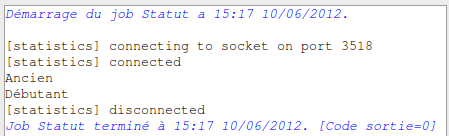
Nous pouvons maintenant passer à la suite !
Les objets
Nous allons maintenant enchaîner par l’alimentation de table OBJET. Commencez par créer un nouveau job Objet puis faites glisser les tables OBJET des bases de données source et destination et reliez le tout avec un tMap comme fait précédemment.
Double cliquez sur le tMap, puis dans la nouvelle fenêtre qui apparaît, faites correspondre automatiquement les champs entre eux en cliquant sur «Auto map !«.
N’oubliez pas d’ajouter un tLogRow pour vérifier les données qui transitent puis exécutez le job. Vous devriez alors avoir le résultat suivant :
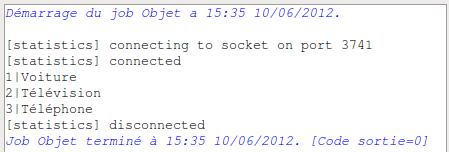
Les utilisateurs
Commencez par créer un nouveau job Utilisateur puis faites glisser les tables UTILISATEUR des bases de données source et destination et reliez le tout avec un tMap comme fait précédemment.
Double cliquez sur le tMap pour faire apparaître la fenêtre des correspondances. Liez les champs UTI_ID, UTI_NOM, UTI_PRENOM et UTI_LOGIN qui ne vont pas nécessiter un traitement particulier et qui peuvent être repris en l’état.
Pour le champ UTI_DATE_INSCRIPTION c’est un peu plus compliqué. En effet, on souhaite ici transformer une chaîne de caractères en date. Pour se faire, nous devons nous rendre dans l’onglet Editeur d’expression du champ UTI_DATE_INSCRIPTION du mapUtilisateur.
Pour transformer une date en chaîne de caractères, nous pouvons utiliser la fonction TalendDate.parseDate qui prend deux paramètres : le format de la date à parser et la date à parser.
Dans notre cas, la date est au format dd/MM/yyyy, ce qui nous donne :
TalendDate.parseDate("dd/MM/yyyy",row1.UTI_DATE_INSCRIPTION )
Mais le problème c’est que la date d’inscription peut-être null, ce qui risque de poser problème. Nous devons donc gérer ce cas avec une condition ternaire comme l’impose Talend. Voici alors ce que ça donne :
(row1.UTI_DATE_INSCRIPTION == null) ? null :
TalendDate.parseDate("dd/MM/yyyy",row1.UTI_DATE_INSCRIPTION)
Il est maintenant temps de s’attaquer au champ UTI_PASSWORD. Dans la base de données source, le mot de passe est en stocké en clair ce qui est une erreur de sécurité. Nous allons donc le hasher. Dans l’exemple, c’est le MD5 qui est utilisé, mais libre à vous d’utiliser du SHA1 par exemple.
Le but est ici de créer un morceau de code Java qui va se charger de hasher le paramètre que l’on va lui fournir en entrée. Cette opération est possible grâce à une routine.
Allez dans l’onglet de gauche, puis dans Code, faites un clic droit sur Routines puis sélectionnez Créer une routine. Donnez lui le nom MD5 puis cliquez sur Terminer.
Une classe java MD5 est alors créée. Voici comment la compléter (algorithme trouvé ici) :
package routines;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
public class MD5 {
public static String getMD5Password(String password) {
byte[] uniqueKey = password.getBytes();
byte[] hash = null;
try {
hash = MessageDigest.getInstance("MD5").digest(uniqueKey);
}
catch (NoSuchAlgorithmException e) {
throw new Error("MD5 non supporté");
}
StringBuffer hashString = new StringBuffer();
for(int i = 0; i < hash.length; ++i) {
String hex = Integer.toHexString(hash[i]);
if(hex.length() == 1) {
hashString.append('0');
hashString.append(hex.charAt(hex.length()-1));
}
else {
hashString.append(hex.substring(hex.length()-2));
}
}
return hashString.toString();
}
}
Maintenant que notre routine est terminée, retournons sur notre tMap et plus particulièrement dans l’éditeur d’expression du champ UTI_DATE_INSCRIPTION du mapUtilisateur. Voici la syntaxe pour faire appel à notre routine fraîchement écrite : routines.NomRoutine.NomMéthode(paramètre). Ce qui donne dans notre cas :
routines.MD5.getMD5Password(row1.UTI_PASSWORD)
Il ne nous reste plus que le champ STA_ID à gérer. Double cliquez sur le tMap et placez-vous dans l’éditeur d’expression du champ STA_ID du mapUtilisateur.
On va tricher un peu en allant consulter directement dans MySQL la table statut. Voici ce que ça donne chez moi :
| STA_ID | STA_NOM |
|---|---|
| 1 | Ancien |
| 2 | Débutant |
Voici donc l’expression qui en découle :
(row1.UTI_STATUT_COMPTE == null) ? null :
(row1.UTI_STATUT_COMPTE.equals("Ancien")) ? 2 : 1
Vous pouvez exécuter !
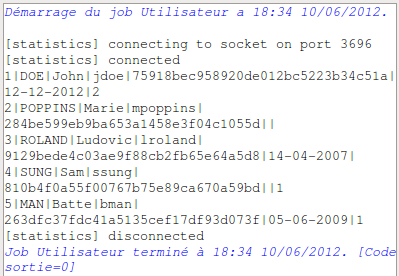
La table UTILISATEUR_OBJET
Puisque les identifiants des utilisateurs et des objets sont identiques entre les deux bases de données, la reprise de données va être ici grandement simplifiée.
Commencez par créer un nouveau job Utilisateur_Objet puis faites glisser la table UTILISATEUR de la base de données source et la table UTILISATEUR_OBJET de la base de données destination et reliez le tout avec un tMap et un tLogRow.
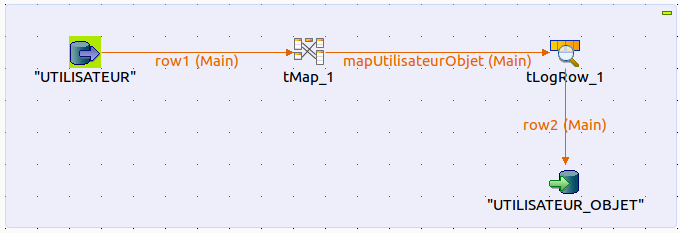
Double cliquez ensuite sur le tMap. Un petit coup d’»Auto map !» puis le tour est presque joué ! En effet, nous devons maintenant éliminer les utilisateurs qui n’avaient pas un objet. Nous allons donc placer un tFilterRow avant le tMap et filtrer la valeur null du champ OBJ_ID.
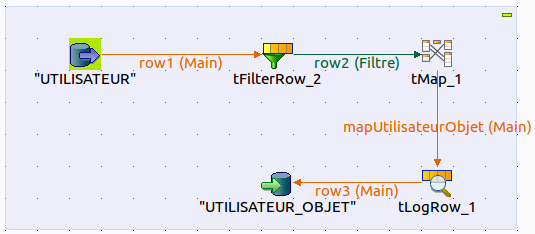
Configurez le filtre comme dans la capture d’écran ci-dessous :
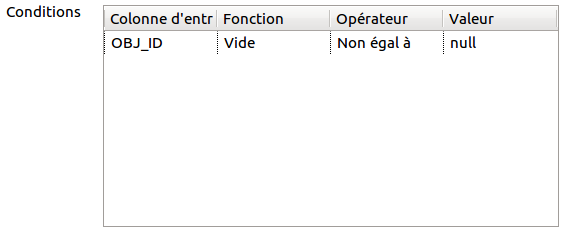
Il ne vous reste plus qu’à exécuter :
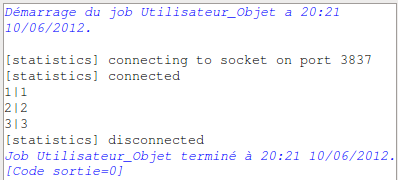
Ce tutoriel est maintenant terminé !