Superviser son application mobile (2/3) : Les bugs trackers
25 octobre 2020
Continuons notre étude des outils relatifs à la supervision des applications mobiles avec les bugs trackers.
Plan
- Superviser son application mobile (1/3) : Les analytics trackers
- Superviser son application mobile (2/3) : Les bugs trackers
- Superviser son application mobile (3/3) : Le bêta test et le déploiement par étape
A la découverte des bugs trackers
Un bug trackers est un outil permettant de remonter des éléments relatifs à une anomalie dans votre application. Ces anomalies peuvent se manifester de différentes formes :
- les crashs, également appelées exceptions non gérées ;
- les exceptions gérées ;
- les anomalies fonctionnelles.
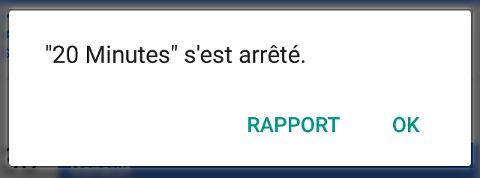
Le crash
A la vie de la précédente énumération, vous vous en doutez, un crash est la forme la plus violente d’un bug. Ils sont facilement identifiables puisqu’ils provoquent purement et simplement la fermeture de l’application au cours de son utilisation. Suivant les plate-formes, un message “système”, c’est-à-dire un message géré et généré par le système d’exploitation peut s’afficher. C’est par exemple le cas sur Android.
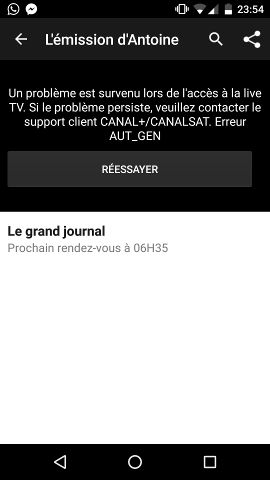
Les exceptions gérées
Une exception gérée est une forme un peu moins violente d’une anomalie car elle est capturée, analysée et traitée par l’application. Bien que l’écran sur lequel se produit l’exception gérée ne soit pas forcément utilisable, elle s’accompagne généralement d’un message généré par l’application expliquant alors l’origine du problème à l’utilisateur, rendant alors l’expérience utilisateur bien meilleure.
Les anomalies fonctionnelles
Les anomalies fonctionnelles, quant à elles, correspondent plutôt à un dysfonctionnement de l’application. Imaginons par exemple une application de type calculatrice qui répondrait que 1+1=3.
Quelque soit la nature de l’anomalie, à savoir, crash, exception gérée ou anomalie fonctionnelle, les informations remontées par les bugs trackers vont vous permettre de comprendre au mieux, où et comment a eu lieu l’anomalie grâce à de nombreuses informations, comme :
- une stacktrace, c’est à dire un message d’erreur très précis sur l’origine du problème et la ligne du code source où le problème s’est produit ;
- des informations relatives au contexte : le nombre de fois où le bug est apparu, des détails sur les terminaux touchés (marque, modèle, version d’Android, pourcentage de batterie, RAM disponible, etc.), la version de l’application touchée, etc.
Comment et où remonter toutes ces informations ?
Comme pour les analytics trackers, nous devons nous poser la question de comment et où remonter les informations relatives à une anomalie. Avec ce que nous avons vu dans les précédents paragraphes, je suis sûr que vous avez une petit idée de la réponse. Cependant, je vous propose tout de même de voir ensemble quelques éléments de réponse.
Où remonter toutes ces informations ?
Comme nous l’avions fait pour les outils relatifs aux analytics, je vous répondre de répondre tout d’abord à la question “où”.
Je ne vous apprends rien en vous disant que le principe est exactement le même que pour les analytics : les données relatives aux incidents qui se produisent dans vos applications doivent être remontées vers une plate-forme sur laquelle vous serez en mesure de les lire et les interpréter pour ensuite les corriger. Une nouvelle fois, cette plate-forme pourrait être une base de données accessible depuis un serveur.
Comment remonter toutes ces informations ?
Voyons maintenant comment il est possible de remonter ces fameuses informations relatives à un incident survenu dans votre application. Ne changeons rien et suivons la même logique que pour la remontée des données relatives à l’usage de votre application : intégrer à l’application mobile concernée une petite brique logicielle capable de communiquer avec la plate-forme en charge de recueillir et stocker les informations. Une nouvelle fois, nous pouvons imaginer faire communiquer la fameuse brique logicielle et la plate-forme à l’aide de requêtes HTTP ou à l’aide d’un socket.
Continuons sur notre lancée et enchaînons immédiatement par l’étude des moyens dont vous disposez pour remonter toutes ces informations. Comme pour les analytics trackers du précédent chapitre, nous allons distinguer deux façons de faire : la façon “industrielle” et la façon “artisanale”.
La manière “artisanale” consiste à tout faire soit même que ça soit la brique logicielle à intégrer dans l’application mobile et capable de détecter les incidents et récupérer les informations qui leur sont relatives, que la plate-forme en charge de recueillir ces fameuses informations, les afficher, etc. C’est un travail monstre que vous aurez très peu de chance de réussir si vous êtes débutant. En effet, votre outil doit être capable d’intercepter toutes les anomalies qui apparaissent dans votre application, ce qui en soit est déjà un gros travail, et vous devez en plus penser à tous les scénarios d’utilisation possible afin d’adapter le comportement de votre outil. Par exemple :
- Comment se comportera la brique logicielle, si je fais le choix de la faire communiquer avec ma plate-forme via des requêtes HTTP et que l’application est utilisée sans une connexion internet ? Vais-je ignorer les incidents bien qu’ils soient très précieux ?
- Suis-je alors capable de créer une brique logicielle qui sera en mesure de garder en mémoire toutes les informations tant qu’elles n’ont pas été transmises à ma plate-forme ?
- Suis-je capable de créer un composant capable de gérer la reprise sur erreur ?
Bref, en lisant les prochaines lignes de ce cours, vous allez vite vous rendre compte que parfois réinventer la roue n’est pas utile quand d’autres ont fait le travail pour nous !
Si je vous décourage de créer votre propre composant, c’est que d’autres ont déjà créé des composants très poussés et qui fonctionnent très bien. Autant réutiliser leur travail !
Étudions donc la façon que je qualifie d’“industrielle” qui, dans sa philosophie, s’oppose à la méthode “artisanale”. Si la méthode “artisanale” consiste en un travail “manuel”, la méthode “industrielle” consiste quant à elle à utiliser des outils proposés sur le marché et ayant fait leurs preuves. Nous allons voir qu’il en existe aussi bien des gratuits que des payants.
Comme pour les produits permettant de remonter des analytics, les produits permettant de remonter les incidents qui se produisent dans vos applications sont nombreux. Il n’existe, à mon avis, pas un meilleur que les autres. Si vous devez en utiliser l’un d’eux, je vous conseille d’en essayer plusieurs et de vous faire votre propre idée.
Avant même de vous délivrer le nom de quelques produits connus et très utilisés dans le monde professionnel, j’aimerais revenir rapidement sur les avantages qu’ils présentent par rapport à une solution maison :
- ils disposent, pour la plupart, d’une plate-forme accessible au travers d’un navigateur web ; cette plate-forme, très graphique, vous permet de rapidement vous rendre compte de l’impact des différents incidents sur votre application ;
- la brique logicielle à intégrer au sein de l’application mobile et permettant de remonter les incidents est généralement robuste (gestion de de la présence ou non de réseau, reprise sur erreur, etc) et vous mâche généralement le travail (quelques lignes de code seulement permettent de remonter les anomalies).
Quelques bug trackers connus
Dans les prochaines lignes, je ne vais pas faire la liste complète et détaillée de tous les bug trackers qui existent cependant, je vous propose un cours paragraphe sur deux d’entre eux qui sont massivement utilisés dans le monde professionnel.
Crashlytics
Le premier dont nous allons parler est Crashlytics. Cet outil, gratuit, est la proprié. A noter que cet outil fait partie d’une suite logicielle nommée Firebase.
En savoir plus sur Crashlytics.
D’autres solutions
Je ne reviendrai pas en détail sur les autres outils disponibles sur le marché, mais sachez qu’ils sont nombreux et méritent qu’on s’y attardent. Parmi les solutions très utilisées dans le domaine professionnel, nous pouvons par exemple citer :
- Splunk MINT, anciennement nommé Bugsence, cet outil payant est bien plus qu’un bug tracker puisqu’il est possible d’analyser la couche réseau de votre application et bien plus ;
- New Relic ;
- ACRA, cet outil gratuit présente l’inconvénient de ne pas être fourni par défaut avec une plate-forme sur laquelle remonter les anomalies, il convient alors d’utiliser une plate-forme tierce.
En résumé
- les bugs trackers permettent de remonter les anomalies qui apparaissent dans votre application ;
- les bugs trackers sont important pour comprendre le contexte dans lequel un bug s’est produit ;
- les bugs trackers peuvent mettre en lumière un dysfonctionnement grave au sein de vos applications mobiles ;
- les informations remontées à l’aide d’un bug trackers doivent être consultées régulièrement et être prises en considération pour proposer des mises à jour de qualité à vos utilisateurs.